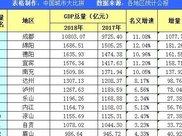
所掌握的知识是告诉我们现在这三个历法系统 , 它对应的日期应该是同一天 。 这里恰好找到红色是1、蓝色是6的这一行 , 对应的破译结果是长历的创世以来第275520天 , 恰好是神历中一年的倒数第三天 , 也恰好是太阳历中第13个月的第14天 , 一切都一致了!于是 , 这就得到了结果 。
这就是反绎的过程 。
我们回顾一下 , 首先它来自一个不完备的观察 , 有的图像是什么我们知道 , 有的图像是什么我们不知道 。 然后基于这个观察 , 我们得到一个假设 。 有了这个假设之后 , 根据我们的知识来找一个最可能的解释 。 而这个解释就是现在红色 , 蓝色这个我们当前所关心的集合 。 这就是反绎的含义 。
反绎学习的设置不太一样 。 我们有一些样本 , 但只有样本的表现 , 不知道结果 。 这就类似于刚才在玛雅这个故事里面我们看到很多图像 , 但这个图像对应的含义是什么还不知道 。 反绎学习中假设有一个知识库 , 这就类似于刚才考古学家所拥有的关于历法的知识 。 同时我们还有一个初始分类器 , 这就好比说考古学家一开始看到这个图像 , 他会猜这个图像到底是什么?那么他凭什么猜呢?是他脑子里面有这么一个分类器 。
那么接下来这一步 , 我们就要根据知识库里面的知识来发现有没有什么东西是不一致的?刚才在玛雅历法的故事里 , 第一轮就一致了 , 但在一般的任务中未必那么早就能发现一致的结果 。 如果有不一致 , 我们能不能找到某一个东西 , 一旦修改之后它就能变成一致?这就是我们要去找最小的不一致 。 假设我们现在找到 , 只要把这个非C改成C , 那么你得到的事实就和知识都一致了 。 我们就把它改过来 , 这就是红色的这个部分 。 那这就是一个反绎的结果 。 而反绎出来的这个C , 我们现在会回到原来的label中 , 把这个label把它改掉 , 接下来我们就用修改过的label和原来的数据一起来训练一个新分类器 。 这个过程可以不断地迭代下去 。 这个分类器可以代替掉老的分类器 。 这个过程一直到分类器不发生变化 , 或者我们得到的事实和知识库完全一致 , 这时候就停止了 。
推荐阅读
-
请问15岁的女生吃富马酸喹硫平接近一年,每天吃四片的富马酸喹硫平片,对我的大脑和神经会有影响吗
-
-
华为华为P50最新确认,一体全视屏+鸿蒙OS+双8500万,这才是华为
-
文史漫今生少年成名诗传长安,为何老来落寞,诗仙李白奋斗史
-
充电宝■同样是共享模式,为什么只有共享充电宝活的滋润?
-
-
『大众CC』吉利全新旗舰车型!1.5T榨出180马力,油耗5.8L,比大众CC时尚
-
-
在高速上行车,碰到这4种标线一定要当心,交警:第四种12分扣完
-
『地区气温』今日又将升温!重庆各地最高气温普遍超30℃
-
-
-
外卖|外卖小哥闯红灯被撞倒,深圳交警提醒骑手遵守交通法规
-
-
医院|津巴布韦首家“中国标准”新冠诊疗医院投入使用
-
北京经信局潘锋:利用区块链技术建金融专区,解决小微企业贷款难
-
-
-
-