数据库:阿里巴巴为什么能够抗住90秒100亿?看完我哭了。

文章图片

文章图片

文章图片

文章图片

文章图片
文章图片

文章图片

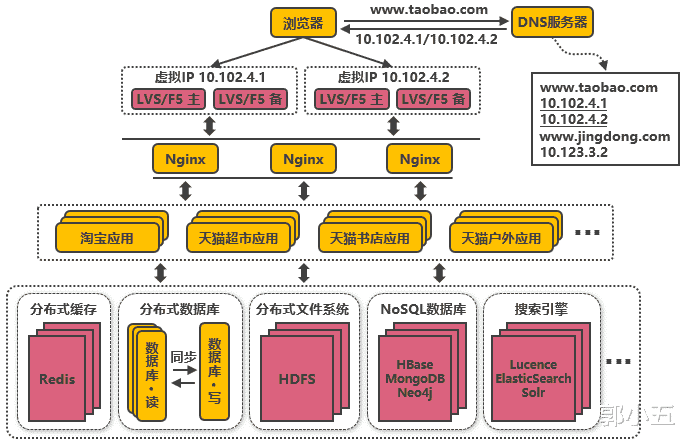
今天看了一篇文章 , 介绍了淘宝从一百并发到千万级并发的情况下服务端的架构演变过程 , 是如何从一个单体系统 , 发展到云平台承载系统 , 是如何避免了走向单体架构的深渊 。 首先要明白什么是搞可用?什么是分布式?所谓分布式就是系统中多个模块在不同的服务器上部署 , 即可称为分布式系统 , 比如Tomcats和数据库分别部署在不同的服务器上 , 或者两个相同的功能的Tomcat分别部署在不同的服务器上面 。 至于高可用就是系统中部分节点失效时 , 其他节点可以继续提供服务 , 打比方说你是一名女性 , 你男朋友A某正在打游戏不接电话 , 而你想要去逛街 , 于是乎你把逛街的请求发送给了替补队员B某 , 从而保证了服务不间断的运行 , 这就叫高可用 , 也叫作故障切换 。
切入正题了解一下淘宝的演变过程 , 在网站最初的时候 , 应用数理于用户的数据都比较少 , 可用把Tomcat和数据库部署在同一台服务器上面 。 浏览器向淘宝网站发送请求时 , 首先经过DNS域名解析把域名转换为IP地址 , 浏览器转而访问该IP地址对应的Tomcat , 但是随着用户数量的加大 , Tomcat和数据库之间竞争资源 , 单体性能这时候不足以支撑业务完成服务 。
单体
第一次演变 , Tomcat和数据库的读写分离 , 数据库和Tomcat分别占用单独的服务器资源 , 各自的性能显著的提高 , 但是用户数的增长 。 并发读写数据成为了数据的瓶颈 。
读写分离
第二次演变 , 加入本地缓存和分布式缓存在Tomcat同服务器上或同JVM中增加本地缓存 , 并在外部增加分布式缓存 , 缓存热门商品信息或热门商品的html页面等 。 通过缓存能把绝大多数请求在读写数据库前拦截掉 , 大大降低数据库压力 。 其中涉及的技术包括:使用memcached作为本地缓存 , 使用Redis作为分布式缓存 , 还会涉及缓存一致性、缓存穿透/击穿、缓存雪崩、热点数据集中失效等问题 。 虽然缓存抗住了大部分的访问请求 , 随着用户数的增长 , 并发压力主要落在单机的Tomcat上 , 导致响应逐渐变慢 。
分布式缓存
第三次演变引入反向代理实现负载均衡在多台服务器上分别部署Tomcat , 使用反向代理软件(Nginx)把请求均匀分发到每个Tomcat中 。 此处假设Tomcat最多支持100个并发 , Nginx最多支持50000个并发 , 那么理论上Nginx把请求分发到500个Tomcat上 , 就能抗住50000个并发 。 其中涉及的技术包括:Nginx、HAProxy , 两者都是工作在网络第七层的反向代理软件 , 主要支持http协议 , 还会涉及session共享、文件上传下载的问题 。 反向代理使应用服务器可支持的并发量大大增加 , 但并发量的增长也意味着更多请求穿透到数据库 , 单机的数据库最终成为瓶颈.
推荐阅读















- 『软件』明知有的副业是骗人的,为什么还是有很多人去做呢?
- 阿里巴巴▲三国志战略版什么来路?为何频频刷屏各大软件?
- 阿里巴巴■公有云竞争格局:阿里云一枝独秀,华为实现弯道超车
- 『阿里巴巴』雷军喜提“100亿”!问题来了,雷军还能超过马云马化腾吗?
- 火星:明明距离地球最近的行星是金星,为什么全世界却都赶着去探测火星?
- 5g手机@5G手机出来许久,为什么大家都不买?这4个原因足以说明!
- 阿里巴巴@阿里巴巴淘小铺到底是不是“天时地利人和”的赚钱机会
- [阿里巴巴]阿里找台积电代工,中芯国际“失败了”?网友:不要忘记华为经历
- 「」9个出人意料的事物,能让你,变成十万个为什么!
- 高通骁龙▲为什么懂手机的人建议选择麒麟820手机,而不是骁龙765G?